TCPのお話。急なスパイクとかとコネクションについてとか
対象読者
TIME_WAITのお話
「サービスが落ちた!」「負荷率は大したことないぞ!」「CPU, MEM, LoadAvarage, diskIO異常なし!」 な状態でもサービスが落ちるケースは存在します。 その一つが「ポート枯渇」問題です。 そんな時に疑われるのが「TIME_WAIT」状態のコネクションが滞留しているケースです。
LinuxにおけるTCP
enum { TCP_ESTABLISHED = 1, // パッシブ・オープンで、待ち受け状態 TCP_SYN_SENT, // アクティブ・オープンで、SYNを送信した状態 TCP_SYN_RECV, // アクティブ・オープンのSYNに対してACKとSYNで応答し、それに対するACKを待っている状態 TCP_FIN_WAIT1, // FINを送信して、それに対する応答を待っている状態 TCP_FIN_WAIT2, // 送信側のクローズ処理が終了し、相手からのFINを受信するのを待っている状態 TCP_TIME_WAIT, // 「CLOSING」でACKを受けた状態 TCP_CLOSE, // TCP_CLOSE_WAIT, // パッシブ・クローズの状態 TCP_LAST_ACK, // 「CLOSE_WAIT」で送信したFINに対するACKを待つ状態 TCP_LISTEN, TCP_CLOSING, TCP_NEW_SYN_RECV, TCP_MAX_STATES };
それぞれの状態についてはnetstatやssコマンドで取れたり、/proc/net/tcpを確認することで確認できます。 TCP パケットは性質上コネクションの状態を制御するためフラグ/シーケンス/ACK/ウィンドウのフィールドを持ちます。
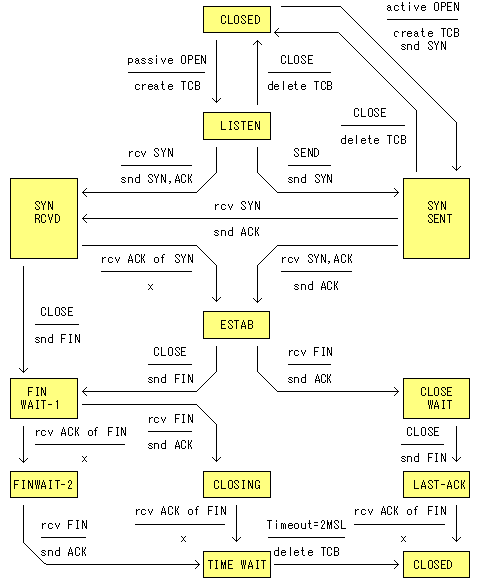
状態についてはRFC793で定義されている上記の図をご確認ください。
/proc/net/tcp
/proc/net/tcpについては初見では何が書いてあるのかわかりません。
root@poc 03:01:30 ~ # cat /proc/net/tcp sl local_address rem_address st tx_queue rx_queue tr tm->when retrnsmt uid timeout inode 0: 0B00007F:9099 00000000:0000 0A 00000000:00000000 00:00000000 00000000 0 0 29239 1 0000000000000000 100 0 0 10 0
ドキュメントを探っていると下記のような記載がありました。
It will first list all listening TCP sockets, and next list all established TCP connections. A typical entry of /proc/net/tcp would look like this (split up into 3 parts because of the length of the line): 46: 010310AC:9C4C 030310AC:1770 01 | | | | | |--> connection state // ステータス | | | | |------> remote TCP port number // 接続元のポート番号 | | | |-------------> remote IPv4 address // 接続元のIPアドレス | | |--------------------> local TCP port number // ローカルポート番号 | |---------------------------> local IPv4 address // ローカルIPアドレス |----------------------------------> number of entry
TIME_WAITとは
TCPのコネクションの終了はとてもとても丁寧に行われます。 先ほど貼った図を見ればわかりやすいと思いますがFINフラグを用いて終了確認をきちんと行っているタイミングがあります。 勝手に片方が切断するといったことを許していません。
FINを送った側は送った瞬間からデータを送信することはなくなり単方向でのデータ送信となります。
TIME_WAIT状態は、サーバ側からクライアントに対してセッションを切断した状態です。 コネクション終了要求応答確認(送信したACK)がリモートホストが確実に受取るのを待つ。待機時間が終了したらCLOSEDに遷移します。 (ちなみにこの仕組みは同一ポートを別プロセスが利用するのを防ぐためのTCP規格です。)
TIME-WAIT – represents waiting for enough time to pass to be sure the remote TCP received the acknowledgment of its connection termination request.
netstat
netstatは上記のファイルをみてactiveやpassiveなポートを見る以外にも サーバ起動時からのコネクションの統計情報を表示することも可能です。 下記項目について表示される数値はパケット数ではなくコネクション数となります。
$ netstat -s | grep Tcp: -A 10
Tcp:
148714 active connections openings
317 passive connection openings
258 failed connection attempts
302 connection resets received
8 connections established
1055198 segments received
1308497 segments send out
101466 segments retransmited
2 bad segments received.
1712 resets sent
| 項目 | 概要 |
|---|---|
| active connections openings | Active Open総数 |
| passive connection openings | Passive Open総数 |
| failed connection attempts | 接続失敗数 |
| connection resets received | リセット接続数 |
| connections established | 現在のコネクション総数 |
| segments received | 受信されたTCPセグメント(データ)数 |
| segments send out | 送信されたTCPセグメント(データ)数 |
| segments retransmited | 再送されたTCPセグメント(データ)数 |
| bad segments received | 不正なセグメントの受信数 |
コンテナでのコネクション数
ここまでみてきた中で新たな疑問。 コンテナ内でのnet.core.somaxconnはどんな値になってるのか。
Dockerコンテナ内主要なimageのsomaxconnは128となっています。 net.core.somaxconnとは接続要求を待ち受けることができるキューのことです。 この値以上のコネクションが同時にきた場合はクライアント側へエラーを返す仕様となっています。
デフォルトの128では心許ないので増やしたいのですがコンテナ内のprocfsはread onlyで書き込みができません。 (この値はホストの値とは関連性はなくコンテナ内独自のカーネルパラーメータとなります。) そこで--sysctlというオプションを使って値を調整します。 ちなみにdocker-composeでやるなら下記のように設定します。
sysctls:
net.core.somaxconn: 2
net.ipv4.ip_local_port_range: "10000 60999"
ちなみにこの機能はdocker 1.12から追加された機能です。 その際のPRがこちら。
負荷が高いサーバーでは接続要求をdropしてしまう可能性があるのでこの値を適切に設定する必要がありそうです。 (webサーバとかプロキシサーバなどが当てはまる。あとはdbサーバも)
覚えておこう
対策
カーネルパラメータでbacklog、somaxconnを調整する。 プロセスのbacklog数も設定可能であれば調整する
# 設定 $ sysctl -w net.ipv4.tcp_tw_reuse=1 # 確認 $ sysctl -n net.ipv4.tcp_tw_reuse 1
| パラメータ | 概要 |
|---|---|
| net.ipv4.tcp_tw_reuse | TCPの接続を使いまわすかどうか |
まとめ
TCPは奥が深いです。 今回参考にした書籍は下記のいわゆるエンジニアのバイブル的な本。
次はウィンドウやフローに関してかければいいなと思ってます。